A script to automatically extract good screenshots from YouTube videos
Introduction
As some of you readers may already know, one of my side projects involves the digital preservation of old brazilian CD-ROMs. One of the several manifestations of this project is the “brazilian CD-ROM directory”, a fun web UI where the user can peruse these CDs and find more about them:

Although I’m proud of the page and honestly believe that it looks great, one thing that always annoyed me is how it lacks the screenshots of each game.
Sadly, taking screenshots is very time-consuming, even when you’ve already recorded the whole game (which is the case for several games in the page). Roughly: you have to open up the video, select the timestamps which you deem most “representative of the video”, press print screen, select the video dimensions, click to save the screenshot, and finally name it appropriately. This takes only a few seconds if you’re in the zone, granted, but I bet you wouldn’t want to do this hundreds if not thousands of times! There are many ways in which this process could be improved: for instance, if we opened the video in VLC and pressed Shift+S to automatically screenshot the current frame, this would save us time as the screenshot would automatically be saved with an appropriate name in the correct folder.
However, if we’re going to automate some things, why not automate the whole process? This is the line of thought which led me to writing a simple Python script that automatically selects screenshots from any video. You can find it below, and in the rest of the post I’ll briefly explain how it works.
"I came to see the code!"
How it works
tl;dr: we take a bunch of screenshots, downscale them, and use $K$-means to select $N$ of them.
Let's take a closer look. The script assumes that you already know how many screenshots you’ll need (let’s call it $N$), and that you already have the video on disk (in my case, I easily downloaded them all using youtube-dl).
(1) The first thing the script has to do is open the video, which is done using Py-OpenCV2. If my memory serves me well, installing this library in a Windows environment is a major pain in the ass -- but thankfully this was already installed in my PC, since in my undergraduate thesis years ago I had to employ Haar Cascade to detect traffic cones (this will be a satisfying callback for those who have been keeping up with the sitcom that is my life).
(2) Next, the script is gonna make a preliminary selection of screenshots. In this step, it is going to take $M \times N$ frames from the video, evenly spaced from beginning to end. Hereafter, I’ll assume $M = 10$, but just know that this is a parameter that can be modified.
My initial idea was to simply select $M \times N$ random frames, but I ultimately decided against using randomness, because I didn’t want to face the temptation of just re-executing the script every time I got a bad result. Instead, I wanted to make the script consistently decent.
 Images are from "Onde Está Wally? No Circo" (1995)
Images are from "Onde Está Wally? No Circo" (1995)
(3) Then, the script downscales every one of these $10 \times N$ frames to a $32\times32$ image. This has the effect of smoothing the image and removing most details, therefore allowing the images to be compared on a more general level.
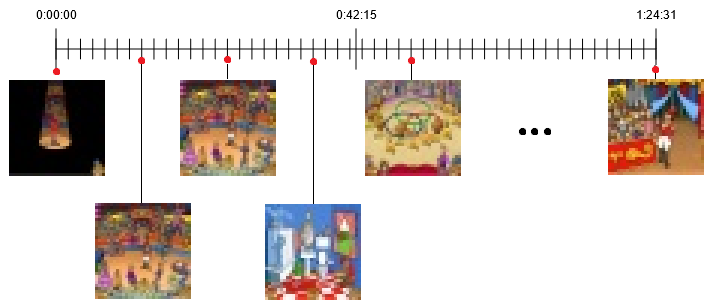
(4) Next, the script runs $K$-means with $N$ clusters. This effectively divides the $10 \times N$ frames into $N$ groups of frames, such that each group is visually distinct from the others (we hope).
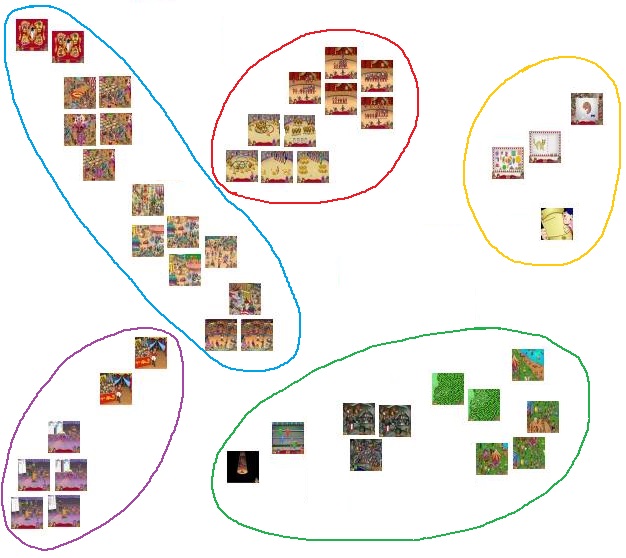
(5) Finally, return the most representative screenshot of each cluster (the frame closest to the centroid). This guarantees that each screenshot is as distinct as possible from the others.
%20-%20CD-ROM%20PT-BR-8XSerKdK1CY._ss1.jpg)
%20-%20CD-ROM%20PT-BR-8XSerKdK1CY._ss2.jpg)
%20-%20CD-ROM%20PT-BR-8XSerKdK1CY._ss3.jpg)
%20-%20CD-ROM%20PT-BR-8XSerKdK1CY._ss4.jpg)
%20-%20CD-ROM%20PT-BR-8XSerKdK1CY._ss5.jpg)
And that’s basically it! It’s very simple, and I refrained from introducing additional complexity because the above procedure produces good enough results for me. Let’s take a look at some of them.
Examples
For the game Imaginemos! - Nosso Mundo É Um Playground (1998), the script produced the following 10 screenshots:
 - CD-ROM Completo PT-BR-OQWm6HR4KBU_ss1.jpg)
 - CD-ROM Completo PT-BR-OQWm6HR4KBU_ss2.jpg)
 - CD-ROM Completo PT-BR-OQWm6HR4KBU_ss3.jpg)
 - CD-ROM Completo PT-BR-OQWm6HR4KBU_ss4.jpg)
 - CD-ROM Completo PT-BR-OQWm6HR4KBU_ss5.jpg)
 - CD-ROM Completo PT-BR-OQWm6HR4KBU_ss6.jpg)
 - CD-ROM Completo PT-BR-OQWm6HR4KBU_ss7.jpg)
 - CD-ROM Completo PT-BR-OQWm6HR4KBU_ss8.jpg)
 - CD-ROM Completo PT-BR-OQWm6HR4KBU_ss9.jpg)
 - CD-ROM Completo PT-BR-OQWm6HR4KBU_ss10.jpg)
As we can see, they are very visually distinct from each other, as we wanted - indeed, in this game you visit many different regions of the world, and each one of the 10 screenshots is from a different region! This is a resounding success, in my opinion.
Good results can also be seen in 101 Dálmatas: Livro Animado Interativo (1999). This is another children’s game that spans many different screens, and just as before, the script dexterously avoided selecting two screenshots from the same screen:








Sadly, it doesn’t always work this well. Escola Diversão - Meus Primeiros Passos (1998) is a children’s game with several activities. If I had to manually screenshot the video, I’d take one screenshot from each of these activities, or at least from the most important ones. Let’s take a look at what the script does:
 - CD-ROM Completo PT-BR-6PC7CfX1Biw_ss1.jpg)
 - CD-ROM Completo PT-BR-6PC7CfX1Biw_ss2.jpg)
 - CD-ROM Completo PT-BR-6PC7CfX1Biw_ss3.jpg)
 - CD-ROM Completo PT-BR-6PC7CfX1Biw_ss4.jpg)
 - CD-ROM Completo PT-BR-6PC7CfX1Biw_ss5.jpg)
 - CD-ROM Completo PT-BR-6PC7CfX1Biw_ss6.jpg)
 - CD-ROM Completo PT-BR-6PC7CfX1Biw_ss7.jpg)
 - CD-ROM Completo PT-BR-6PC7CfX1Biw_ss8.jpg)
 - CD-ROM Completo PT-BR-6PC7CfX1Biw_ss9.jpg)
 - CD-ROM Completo PT-BR-6PC7CfX1Biw_ss10.jpg)
As we can see, the vast majority of the screenshots belong to the same activity: painting animals. This makes sense, since each painting covers up the whole screen and the paintings have huge color variations between them. However, I'd argue that this is not ideal since the painting activity is over-represented -- if I was doing this manually, I'd never take so many screenshots of the same activity! It could be worse: at least the script managed to squeeze in 3 screenshots of other stuff (1, 4 and 5).
Another example of non-ideal results can be seen in A Viagem de Jubileu (1999). For the most part, the screenshots are diverse and cover many different activities, however there are three screenshots that are out of place: one is a screnshot of the credits, and the other two are screenshots of a promotional video that came with the CD-ROM and just happened to be on the same video:
 - CD-ROM Completo PT-BR-uJgY0xgMYRA_ss1.jpg)
 - CD-ROM Completo PT-BR-uJgY0xgMYRA_ss2.jpg)
 - CD-ROM Completo PT-BR-uJgY0xgMYRA_ss3.jpg)
 - CD-ROM Completo PT-BR-uJgY0xgMYRA_ss4.jpg)
 - CD-ROM Completo PT-BR-uJgY0xgMYRA_ss5.jpg)
 - CD-ROM Completo PT-BR-uJgY0xgMYRA_ss6.jpg)
 - CD-ROM Completo PT-BR-uJgY0xgMYRA_ss7.jpg)
 - CD-ROM Completo PT-BR-uJgY0xgMYRA_ss8.jpg)
 - CD-ROM Completo PT-BR-uJgY0xgMYRA_ss9.jpg)
 - CD-ROM Completo PT-BR-uJgY0xgMYRA_ss10.jpg)
It’s expected that these kinds of things would happen — the script does not contain any context about the domain it is being applied to. Computers are fascinating, but they cannot read our minds just yet.
Conclusion
As I’ve hopefully showed in the preceding section, the results are overall very good, with the main problem being that some screenshots are overrepresented or just out-of-place. As a next step, I could do my homework and develop a more complex procedure imbued with domain knowledge (has anyone said deep learning??), but instead I’ve resorted to something simpler: just delete some of the screenshots! I don’t need 10 of them anyway, that’s way too much — I only need like 5.
Is this an admission of defeat? I don’t think so! The screenshotting procedure requires some manual pruning, true, but in a way it works even better: I actually enjoy having some curatorial say in the process, and deleting screenshots does not take much time. It works for me, who knows, maybe it will work for you too :)