 <voltar>
<voltar>

Em 2022, eu comecei a assistir dorama com a minha mãe, numa tentativa de passar mais tempo junto com ela. Foi - e está sendo - surpreendentemente agradável, apesar do meu receio inicial de que minha mãe não fosse curtir algo num idioma tão diferente do nosso. Felizmente deu tudo certo, e o tempo de adaptação foi mínimo - ela ainda acha o idioma estranho e fala que toda comida “parece horrível”, mas isso não impede ela de engajar com a narrativa e aproveitar os dramas.
No entanto, uma das coisas que ainda confunde ela - e me confunde também, pra ser sincero - são os nomes. Não é que a gente misture os nomes dos personagens, é só que é estranho falar os nomes coreanos em voz alta, especialmente porque nós nem sabemos falar muitos dos fonemas envolvidos. Por isso, muitas vezes eu e minha mãe acabamos chamando os personagens não pelos nomes deles, mas por algum apelido que a gente acaba inventando, por exemplo “o pai da advogada” ou “a mulher da loja de penhores” ou “aquele velho escroto que matou a mulher daquele outro cara, não, o outro cara, não, aquele cara que é o pai daquela mulher, isso, o pai da advogada”.
Mas não é só uma questão de familiaridade sonora, também tem toda a questão cultural envolvida. Isso ficou claro pra mim quando assistimos ao primeiro episódio de Reply 1988, um dos doramas mais bem-recebidos dos últimos anos. Nesse episódio, tem uma cena em que a protagonista - chamada “Deok-sun” - reclama em prantos com seus pais que o nome dela é feio, e que ela preferia ter um nome decente como o de seus irmãos, “No-eul” e “Bo-ra”.
Assistindo a essa cena, eu só conseguia pensar em uma coisa: “O quão ruim é Deok-sun?”
Pra descobrir o quão terrível é o nome “Sung Deok-sun”, precisamos trazer esse nome pra nossa realidade brasileira - como ficaria “Deok-sun” traduzido em português?
Apesar da Lia Wyler sugerir o contrário, traduzir nomes não é uma tarefa nada fácil: nomes normalmente tem algum significado (por exemplo, “Pedro” vem do grego e significa “Pedra”), mas esses significados não tem nada a ver com a concepção coletiva que damos a esses nomes enquanto sociedade. Uma noção muito mais interessante pra gente é a ideia de popularidade: de fato, enquanto Deok-sun reclama que o nome dela é feio, ela explicitamente questiona: “Por que sou a única Deok-sun no mundo?”

Agora sim está promissor! A popularidade de um nome é algo mensurável e conhecível, e em particular, é algo mensurável e conhecível com o qual eu já esbarrei no passado: eu sei que existe uma tabela do IBGE com a popularidade de cada nome no Brasil, e eu imagino que deva existir uma tabela parecida do IBGE coreano. A única coisa que falta é fazer um mapeamento 1:1 - o 1º nome mais comum no Brasil é análogo ao 1º nome mais comum na Coréia do Sul, o 2º nome mais comum no brasil é análogo ao 2º nome mais comum na Coréia, e assim por diante. Desse jeito, traduzimos não só Deok-sun, mas também todos os outros nomes disponíveis (inclusive o meu!).
Essa é a ideia central do projeto: usar índices de popularidade pra parear os nomes brasileiros e coreanos. E já que estamos falando de nomes, também me propus a incluir os sobrenomes - aqui a gente faz o trabalho completo.
O projeto então se divide em três partes:
Eis:
Antes mesmo de começar, eu já sabia que conseguir as tabelas seria a parte mais difícil do projeto - simplesmente pelo fato de que ela não depende de mim. Ou essas informações existem, ou elas não existem, e ponto final. A ideia poderia estar morta antes mesmo de começar.
As quatro tabelas que precisamos são da incidência populacional de:
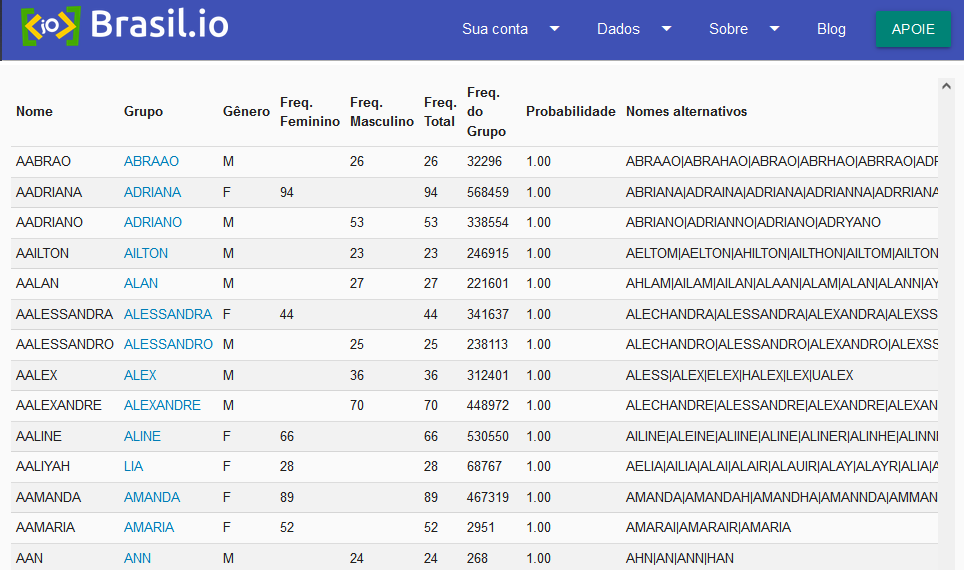
Os nomes em português eu sabia que deviam existir em algum lugar, porque como falei, eu já tive que usar algo assim no passado: existe uma ferramenta web do próprio IBGE que permite ao usuário consultar um nome e descobrir qual a incidência daquele nome na população brasileira. O problema é que uma ferramenta web não é uma tabela, e eu preciso da tabela inteira, imaculada, pura e bela para meu próprio consumo. Consultar nome-a-nome não adianta porque eu quero fazer um mapeamento de todos os nomes.
Felizmente, consegui encontrar exatamente o que eu queria no site brasil.io, que é uma plataforma justamente pra divulgação acessível de dados públicos. A tabela deles tem 100.787 nomes, e inclui também nomes alternativos!!! Perfeito. Um pra baixo, três faltando.
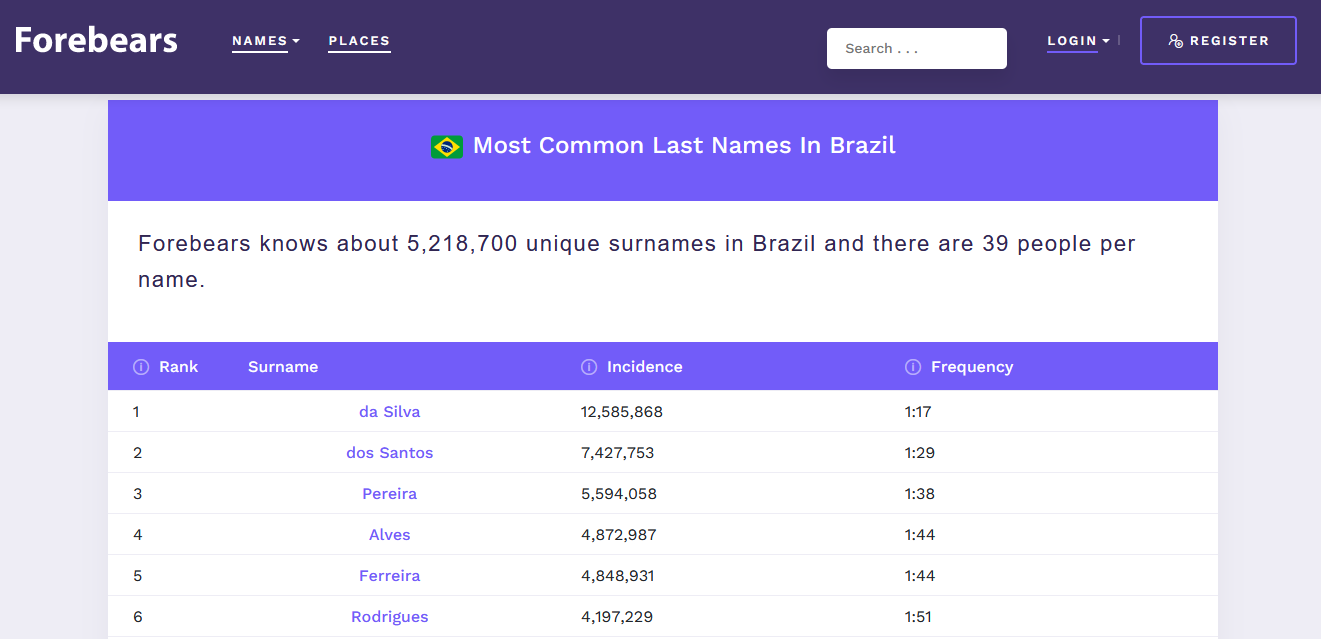
A próxima tabela, dos sobrenomes em português, já começou a elevar a dificuldade do problema. Infelizmente o brasil.io não tem nada com relação a sobrenomes, e de fato, eu não consegui encontrar nada publicamente disponibilizado pelo IBGE nesse sentido. Depois de muito procurar, consegui achar um site chamado forebears.io que é sobre... nomes e sobrenomes?? A página principal do site tem literalmente um botão escrito “Most popular names by country”. Bingo!!!

E de fato, o site tem uma tabela chamada "Most Common Last Names In Brazil”, com os ~1000 sobrenomes mais comuns, em ordem de popularidade. Olhando por cima, os resultados parecem fazer sentido:
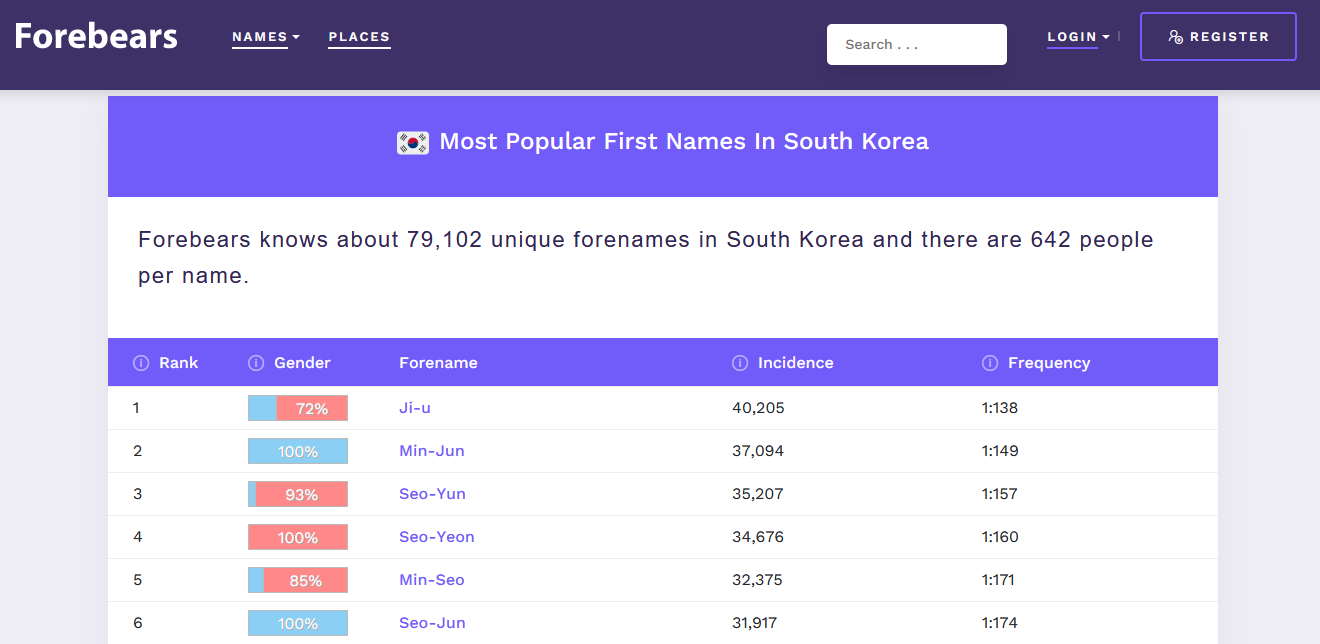
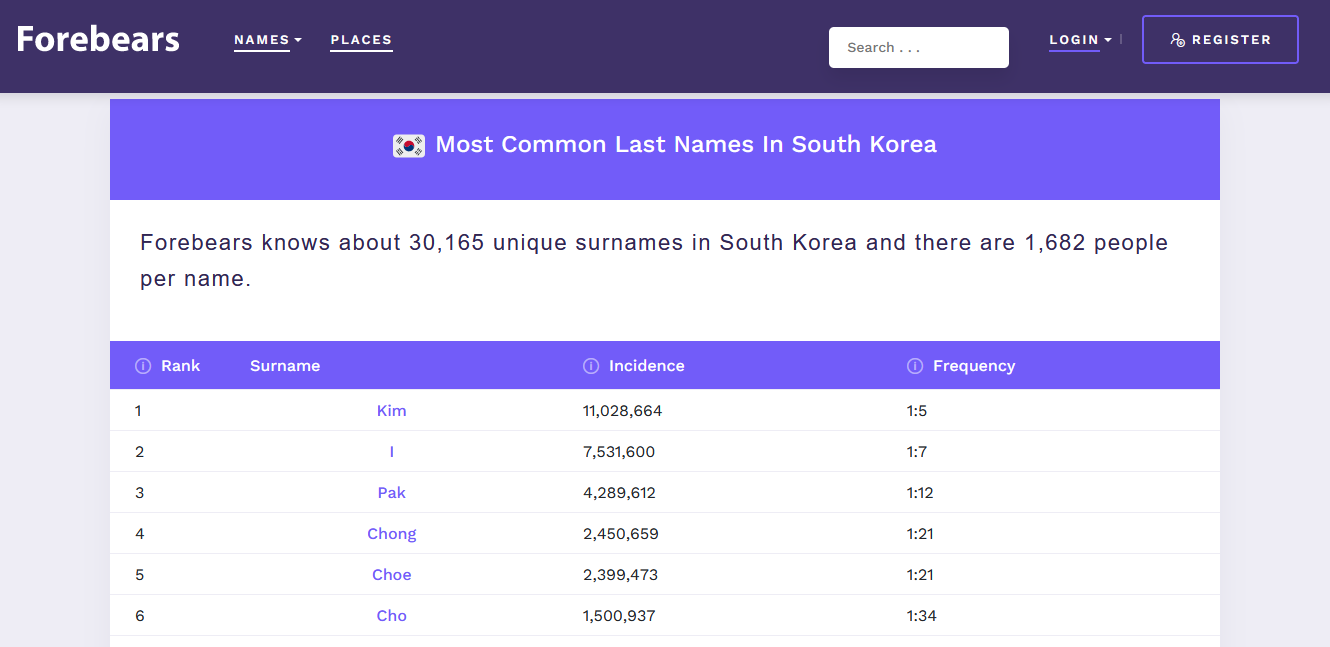
Adicionalmente, o site também tem as mesmas listas pros nomes e sobrenomes em coreano. Duplo bingo!!!!
Na verdade vamos com calma, uma coisa de cada vez. Apesar de ter uma abrangência impressionante e resultados aparentemente corretos (i.e. ”da Silva” ser o sobrenome mais comum me parece aparentemente correto), o Forebears não disponibiliza nenhuma de suas fontes, ou pelo menos nenhuma que eu tenha conseguido encontrar. Além disso, o site diz que conhece “5.218.700 sobrenomes únicos” mas só mostra os 1.000 primeiros... Cadê os outros, Forebears? Diga onde estão os outros nomes ou você vai dormir com os peixes
Infelizmente eu não encontrei nenhuma outra lista de sobrenomes em português na internet, então acabei usando a do Forebears mesmo. Isso não me deixa muito contente, mas considerando que temos isso ou temos nada, eu prefiro ter isso. Garantir a integridade dos dados é importante em princípio, mas não é como se eu tivesse projetando a porra de um foguete aqui
Quanto aos nomes em coreano, usar a lista do Forebears já é um pouco mais complicado, pelo simples fato de que ela não parece “aparentemente correta”: pro primeiro nome mais comum, “Ji-u”, é reportada uma incidência de 40.206 habitantes, o que me parece muito baixo pra um país com... [google população coreia do sul pesquisar]... 51 milhões de habitantes. De fato, eu tenho a forte suspeita de que essa lista não seja dos nomes na população coreana como um todo, mas sim apenas dos nomes nos novos nascimentos! Ou seja, são os nomes mais comuns de bebês - na tabela análoga em português, os nomes mais comuns não seriam “José” e “Maria”, mas “Enzo” e “Valentina”. (A lista de sobrenomes coreanos não tem esse problema, veja que a incidência parece OK)
Por conta disso, decidi me esforçar mais e usei o google translate pra fazer pesquisas direto em coreano, em busca de alguma tabela que pudesse me satisfazer. Infelizmente, mesmo depois de passar noites lendo arquivos excel corormpidos e misteriosos PDFs em coreano, não pude encontrar nenhuma lista de nomes na população geral. O próprio site do KOSTAT, que ao que tudo indica é o IBGE coreano, não tem nada nesse sentido. Fui lentamente levado a acreditar que essa tabela simplemente não existe
Algo interessante que eu encontrei foi o site koreanname.me, que contém explicitamente uma ordenação de nomes por novos nascimentos entre 2008 e 2022. Eu acabei gostando mais desse site do que do Forebears por dois motivos:
O “problema” é que os nomes estão no alfabeto coreano, e não no formato romanizado que a gente sabe (mais ou menos) ler. Felizmente esse problema não é tão difícil de resolver - eu usei a ferramenta chamada “Google” para encontrar um pacote Python que automaticamente romaniza nomes em coreano. Eu não sei o que faria sem as pessoas aleatórias na internet
Com isso, temos uma tabela de nomes em coreano por popularidade, apesar de não ser a popularidade na população e sim nos novos nascimentos da última década e meia. Esse é o alicerce mais fraco do projeto, mas novamente reitero: ou é isso ou é nada, então prefiro que seja isso. Acho que não tem tanto problema, é um projeto de diversão afinal de contas, então deve estar tudo OK contanto que eu escreva um texto longo e enfie essa informação em algum lugar que ninguém vai ler. Eis aqui a informação
Eu vou usar o do Forebears mesmo, porque não encontrei nada melhor, e ele parece aparentemente correto (mesmo caso dos sobrenomes em português).
Com as tabelas em mãos, vamos para a parte divertida!
Pra parear os nomes brasileiros e coreanos, o jeito mais intuitivo é simplesmente botar as tabelas correspondentes uma do lado da outra e parear por posição: o nº nome mais comum em português com o nº nome mais comum em coreano, e o mesmo processo pros sobrenomes. Isso já é o suficiente pra ter algum resultado, mas complicar as coisas é divertido, então respire fundo e me acompanhe.
A distribuição de sobrenomes na Coréia do Sul é muito diferente da distribuição de sobrenomes no Brasil, como mostra esse gráfico que provavelmente ninguém vai entender:
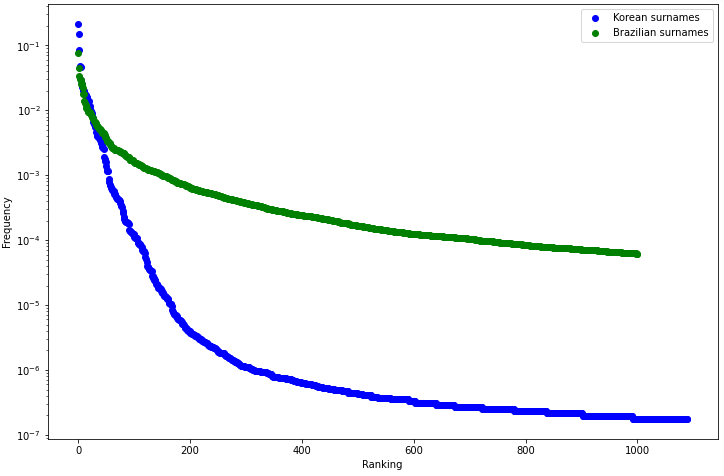
Vê que no início do gráfico os sobrenomes coreanos tem uma frequência maior que os brasileiros, mas depois eles caem pra uma frequência muito inferior? Isso acontece porque os sobrenomes coreanos são muito mais concentrados do que os brasileiros, que é algo que fica evidente quando você analisa a concentração dos três sobrenomes mais comuns nos dois países: ~45% da população coreana tem sobrenome “Kim”, “Lee” ou “Park”, enquanto apenas ~15% da população brasileira tem sobrenome “da Silva”, “dos Santos” e “Pereira”. Em outras palavras, nossos sobrenomes são mais variados, enquanto os deles não.
Por conta disso, um simples pareamento por posição daria resultados estranhos no que tange aos sobrenomes: todo coreano “Kim” viraria um brasileiro “da Silva”, o que é razoável (ambos compartilham a posição #1), mas todo brasileiro “Nóbrega” viraria um coreano “Freeman” (ambos compartilham a posição #528). “Como assim, Freeman? Freeman nem é um sobrenome coreano!” Pois é, a questão é que existem uns ~200 sobrenomes coreanos que são realmente utilizados, o resto é nome de minoria estrangeira; se parearmos por posição, estamos sujeitos a esse tipo de coisa.
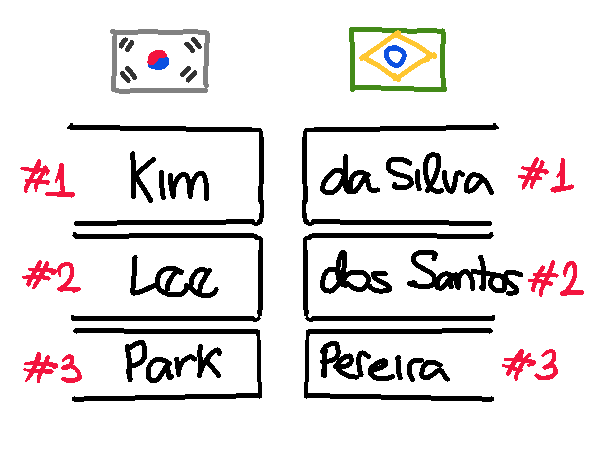
Pra resolver esse problema, podemos usar um pareamento por frequência acumulada. A melhor forma de explicar isso, eu sinto, é com uma imagem. Ao invés de parearmos do jeito acima, pareamos da seguinte forma:

Agora, os primeiros 21,5% da população coreana que se chama “Kim” estão mapeados pros primeiros 21,5% da população brasileira que se chama “da Silva”, “dos Santos”, “Pereira”, “Alves” e “Ferreira”. Os próximos 14,7% da população coreana que se chama “Lee” estão mapeados pros próximos 14,7% da população brasileira, que se chama “Ferreira”, “Rodrigues”, e “Silva”, e assim por diante.
Esse novo pareamento soluciona nosso problema: por exemplo, o sobrenome “Nóbrega” #528 agora está mapeado pro sobrenome “Pyon” #42 (olha que baita diferença). Sucesso!
Infelizmente, o pareamento também introduz dois novos problemas:
Como você resolveria esse problema? Não existe resposta óbvia - eu fiquei um tempo pensando e decidi em uma ideia, mas ela é meio estranha e tenho curiosidade de saber o que as outras pessoas fariam nessa posição. Sinta-se livre pra deixar um comentário sobre a estratégia que você escolheria!
Bom, nossos dois problemas são de escolha entre múltiplas opções, e o jeito mais intuitivo é simplesmente escolher o primeiro. Isso é fácil de implementar, mas cai no mesmo problema de antes: todo “Kim” vira um “Silva”, todo “Lee” vira um “Ferreira”, etc (nesse caso fica ainda pior do que no anterior, porque alguns sobrenomes (ex. “dos Santos”) simplesmente desaparecem).
Uma outra alternativa seria escolher um aleatório. Isso também é fácil de implementar, mas gera uma consequência que eu acho meio desagradável: pessoas diferentes podem botar o mesmo nome e obter traduções diferentes. Se as pessoas realmente forem utilizar essa ferramenta, vai ser no mínimo estranho se essa interação for acontecer: “amiga botei meu nome Maria Ferreira nesse site ele disse que é Kim Soo-hyeon!” “que estranho amiga eu também botei o seu nome e deu que é Lee Soo-hyeon!” “que estranho! acho que esse site está quebrado, vamos apagar ele da nossa mente e processar esse tal de vinizinho”. Entende o que quero dizer? Eu não quero ser processado
Precisamos de alguma função determinística, mas variada, que retorne uma gama grande de nomes mas que não mude de execução pra execução. A forma como eu solucionei isso foi... usando o nome.
Nessa seção até agora eu só falei de sobrenomes. Mas e os nomes, como eles ficam? Bem, em primeiro lugar a distribuição de nomes coreanos e brasileiros é muito parecida:
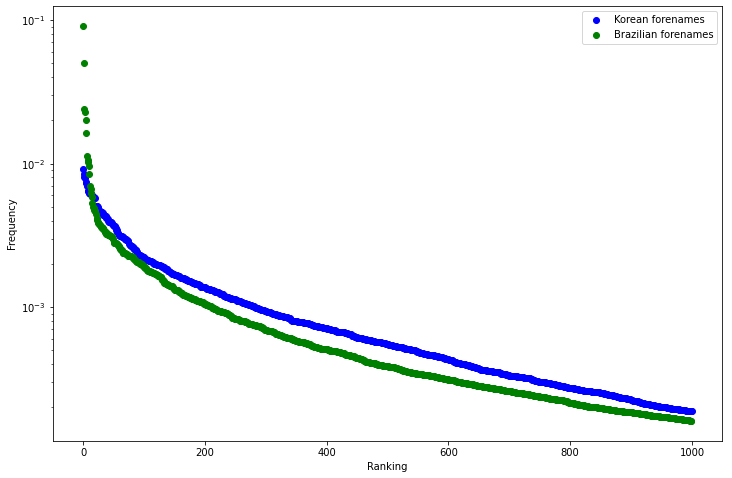
Os nomes mais comuns no Brasil são realmente mais concentrados do que os nomes mais comuns na Coréia do Sul, mas depois disso a distribuição se ajeita e fica bem parecida. Por conta disso, eu decidi que nomes usam pareamento por posição, já que as desvantagens desse tipo de pareamento só ficam evidentes quando as disribuições diferem muito entre si. Isso é uma boa notícia, por dois motivos: primeiro porque agora já resolvemos a questão dos nomes, e segundo porque agora temos uma função determinística e variada pra usar nos sobrenomes!
Sim, é isso mesmo que você leu. Vamos usar os nomes pra definir o sobrenome.
Em particular, vamos usar a posição do nome como uma chave pra definirmos um ponto específico na distribuição do sobrenome coreano. Por exemplo, há uma ambiguidade em como traduzir o sobrenome “Lee” (como vimos anteriormente, pode ser “Ferreira”, “Rodrigues” ou “da Silva”), mas a partir do momento que sabemos que o nome completo é “Lee Min-ho”, podemos usar o fato de que “Min-ho” é o 70º nome coreano masculino mais comum pra definir que pegaremos o ponto 0.07 do “retângulo” de “Lee” (ou seja, o ponto a 7% da distância do início do “retângulo”). A imagem abaixo ilustra esse processo:
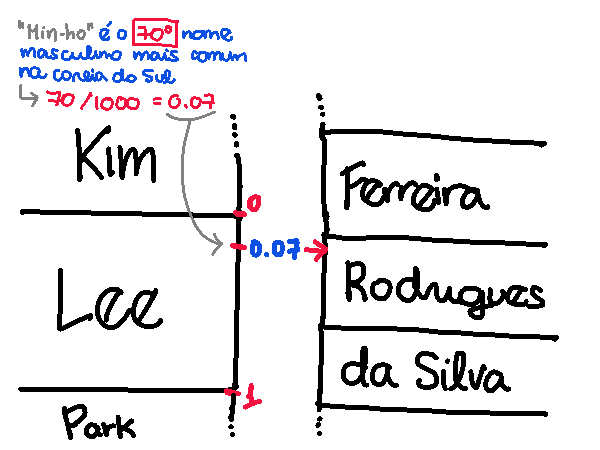
Isso resolve o problema do mapeamento coreano → brasileiro, pois:
Pra fazer isso funcionar no sentido contrário (brasileiro → coreano), a alternativa mais sensata seria fazer exatamente a mesma coisa só que invertido, fazendo 7% a partir do início do retângulo do sobrenome brasileiro em questão. Isso funciona muito bem e é de fato o que foi implementado, a única diferença é que eu incluí um pequeno comportamento extra que faz sentido na minha cabeça mas é um pouco enrolado de explicar. Adentre na caixa caso você não tenha medo de ficar confuso
Se fizermos do jeito descrito acima, é possível que um nome coreano seja traduzido pra português, e a tradução “de volta” nos dê outro nome coreano diferente. Vejamos o exemplo do nome “Lee Min-joo”. Esse nome é traduzido como “José Ferreira”, pois "José/Min-joo" são o 1º nome mais popular no Brasil/Coréia do Sul, e o ponto 1/1000 = 0,001 em "Lee" cai no "Ferreira":
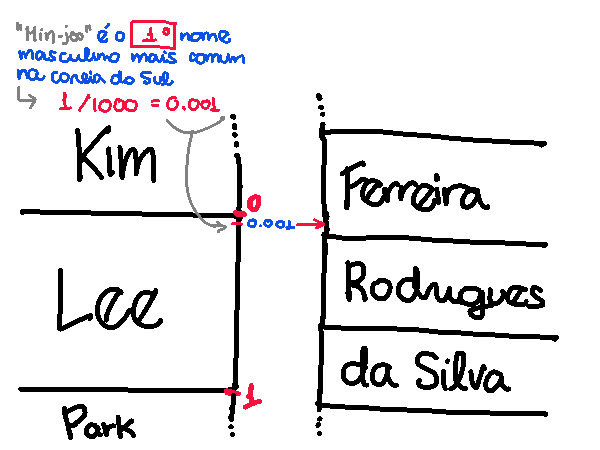
No entanto, se botarmos "José Ferreira" na ferramenta e usarmos o mapeamento brasileiro → coreano delineado acima, olha só o que acontece: o ponto 0,001 em "Ferreira" cai no sobrenome "Kim", não no "Lee"!
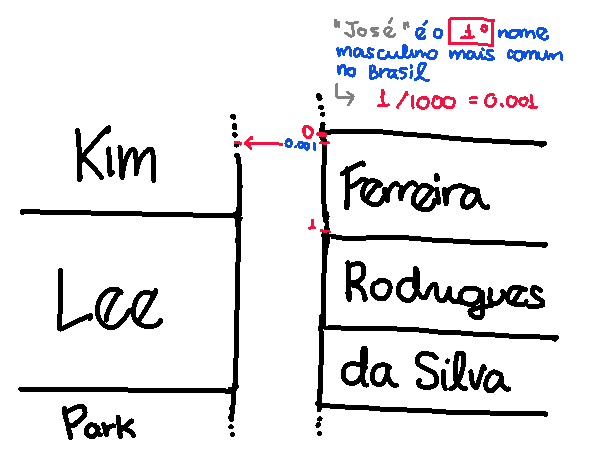
Pra evitar que isso aconteça, toda vez que vou traduzir um sobrenome do português pro coreano, eu primeiro faço um teste de imagem inversa: pra cada “sobrenome coreano candidato” que queremos desambiguar (no exemplo acima, “Kim” e “Lee”), eu simulo como seria uma tradução do coreano pro brasileiro se aquele fosse o sobrenome coreano; se a tradução brasileira bater com o sobrenome que foi inputado, então retorne este sobrenome coreano candidato, caso contrário, use o esquema de desambiguação a partir do sobrenome brasileiro.
No exemplo acima: primeiro o algoritmo traduz “Min-joo” pra “José”. Em seguida, ele descobre que “Ferreira” está sobreposto em “Kim” e “Lee”, e precisa escolher entre um dos dois. Como "José/Min-joo" são o 1º nome mais popular, o programa sabe que o ponto correto seria em 1/1000 = 0,001, mas ele não sabe a qual retângulo esse ponto pertence. Então, ele simula qual seria o resultado de uma tradução coreano → brasileiro pra cada um dos nomes: “Kim Min-joo” seria traduzido pra "José da Silva", e “Lee Min-joo” seria traduzido pra “José Ferreira”. Como o nome que o usuário inputou foi "José Ferreira", então o programa determina que a tradução correta deve ser "Lee Min-joo"!
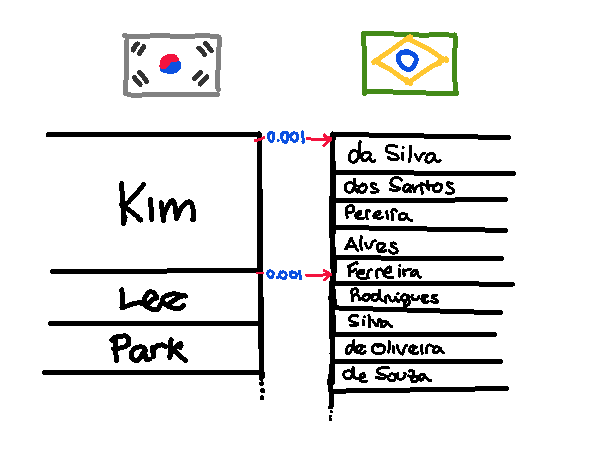
Na prática, isso garante que todas as traduções produzidas pela ferramenta são as mesmas nos caminhos de ida e volta. Não funciona pra todo nome/sobrenome - há casos em que nenhum dos sobrenomes vai resultar no sobrenome original. Nesses casos, aplicamos a regra descrita anteriormente: pegamos o rank do nome, dividimos por 1000, e contamos a partir do início do retângulo do sobrenome brasileiro.
É meio enrolado mas faz sentido eu juro
Com isso, temos um algoritmo de desambiguação razoável! Infelizmente, ele também tem suas desvantagens:
Como estas são desvantagens com as quais posso conviver, declarei concluída a parte de mapeamento entre nomes e sobrenomes, e prossegui pra terceira e última parte: desenvolver a ferramenta web.
Essa foi a parte que demorou mais tempo, apesar de ser a parte que eu menos tenho a dizer (acho que muitas coisas são assim!). Eu já tinha uma boa noção de como queria que ficasse, apesar do meu rascunho inicial não ser particularmente legível pra ninguém que não seja eu mesmo naquele exato momento
Eu não queria que a ferramenta simplesmente recebesse um nome e cuspisse sua tradução; eu queria que ela tivesse algo visual pro usuário entender o motivo daquela tradução, sabe? Mesmo que ele não entendesse nada, pelo menos a informação estaria ali, de alguma forma. Pra isso eu pensei em implementar alguma espécie de roleta usando a mesma analogia visual de retângulos que eu apresentei acima, porque pra mim a noção de pareamento entre as duas listas é totalmente indissociável dessa ilustração de retângulos com alturas variáveis e linhas sendo traçadas.
A biblioteca que costumo usar pra essas coisas visuais na web “mais sofisticadas” é o p5.js. Eu já tenho bastante experiência com ela e gosto muito, o problema é que não acho que ela ia se dar bem com as transições da roleta, além da sincronia entre múltiplas roletas diferentes... até daria pra fazer, sem dúvidas, mas foi pensando em “qual a melhor forma de fazer isso?” que acabei lembrando do D3.js - uma biblioteca que é usada pra fazer visualizações lindas tipo essa. Eu já estou enrolando há alguns anos pra ver qual é que é desse tal de D3.js, então finalmente decidi usar essa oportunidade pra aprender.
O aprendizado fo surpreendentemente tranquilo - no início eu não estava entendendo porra nenhuma, como de praxe, mas depois que eu entendi como o D3.js mapeia data objects e elementos do DOM, as coisas começaram a fluir. Central pro meu aprendizado foram esse vídeo, esse vídeo e essa página. O resto estava ou desatualizado ou me confundindo mais ainda
A primeira coisa que eu fiz não foi nem montar as roletas, mas refazer em D3.js uma página que eu já tinha feito em p5.js. Eu imaginei que seria mais tranquilo porque eu estaria fazendo algo que já sei fazer, então poderia me focar em “como faço isso no D3.js” ao invés de “como faço isso em geral”. Acho que foi uma boa decisão.
Depois de aprender o básico, tomei confiança pra seguir pra ferramenta de tradução.
Antes de falar sobre ela, meu veredito sobre D3.js: é bom! Deu pra ter um gostinho do poder que o D3.js traz. Em particular, é muito mais fácil adicionar transições/animações entre os elementos, e eu também gosto do fato de que posso selecionar o texto dentro dos SVGs. Eu ainda prefiro usar o p5.js quando possível (me dá prazer digitar “rect(0, 0, 50, 50)”, sei lá), mas tem certas coisas que certamente são mais fáceis na framework do D3.js, então fico feliz de ter isso na maleta de ferramentas também.
Sobre a ferramenta em si, não tenho muito a dizer; eu sentei na cadeira e troquei meu escasso tempo no planeta terra por bits e bytes. O processo todo demorou uns 4 dias de trabalho full-time, o que deve dar umas ~30 horas (tudo durante feriados e finais de semana). A ferramenta inicial ficou exatamente do jeito que eu tinha imaginado: três colunas, com a da esquerda sendo o input coreano, a da direita sendo o input brasileiro, e no meio as roletas:
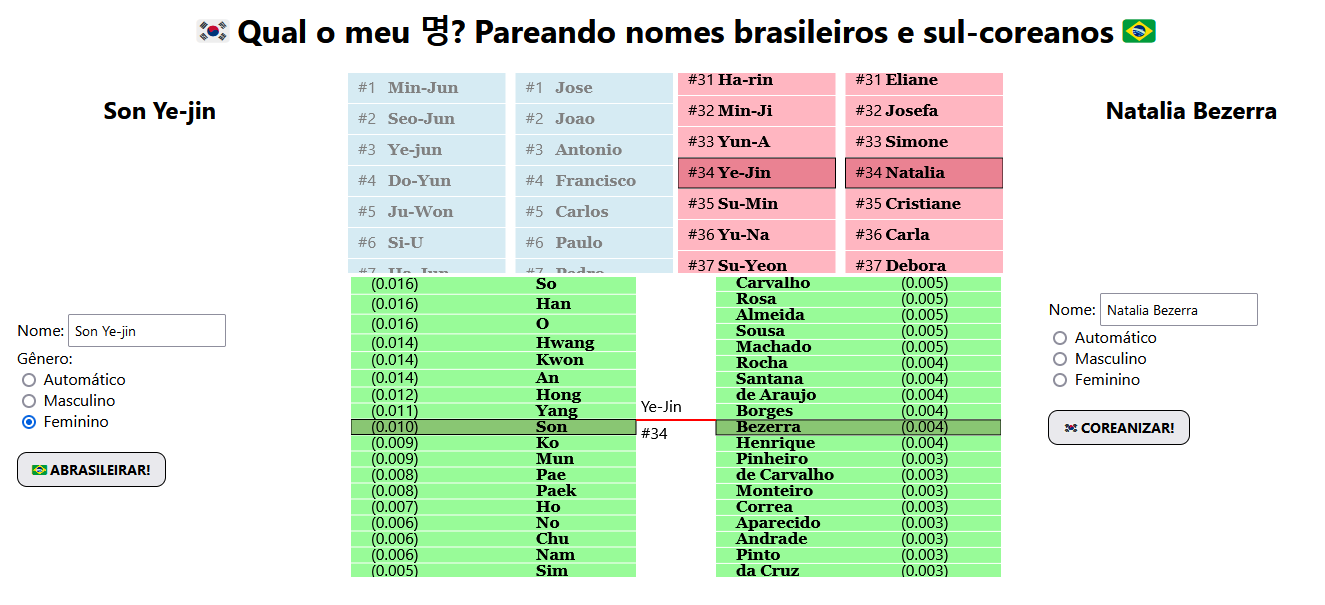
Depois que essa versão inicial estava pronta, eu fiz duas mudanças grandes.
A primeira mudança que eu fiz foi deixar a interface mais mobile-friendly. Na minha experiência com a Bolsodex, 90% das pessoas vêem as coisas no celular, então é fundamental que o site funcione no mobile. Por isso, acabei fundindo o input brasileiro com o coreano (algo que só faz sentido num desktop) e garanti que as colunas ficassem responsivas no celular. Eu acho que no celular ficou claramente inferior ao desktop (ou você olha as roletas ou o input), mas está bem usável, então tô satisfeito.
A segunda mudança foi adicionar um visualizador de imagens de famosos. Isso foi feito usando a API da Wikipédia: se você escreve “Neymar Júnior”, a página faz uma requisição pra Wikipédia e faz uma busca com o termo “Neymar Júnior”. O site então te mostra o título dos artigos retornados (”Neymar”, “Dorival Júnior”, “Vinícius Júnior”) e se você clicar em um dos títulos, aparece a foto principal do artigo.
Por que caralhos eu fiz isso? Dois principais motivos:

Do que isso:
Não foi tão difícil de implementar, então apesar de ser uma coisa meio “feature creep-y”, acho que deu tudo certo no final de contas.
Com essas duas mudanças, a ferramenta chegou na versão atual. Também teve uma terceira mudança a respeito da visualização da roleta de sobrenomes, mas não vou entrar em muitos detalhes aqui porque é meio enrolado. Basta dizer que se a altura dos retângulos de sobrenome for renderizada de forma proporcional à sua frequência na população geral, então o sobrenome Kim (21,54% da população coreana) deve ter uma altura 58.377 vezes maior do que o sobrenome Hwan (0,000369% da população coreana). Em outras palavras: ou um fica invisível, ou o outro fica muito grande. Felizmente a Silvia me ajudou a pensar numa solução pra esse problema; o resultado ficou um pouco menos legal do que eu tinha originalmente imaginado (agora o sobrenome coreano anda separado do sobrenome brasileiro, ao invés de juntos como ocorre na roleta de nomes), mas essa nova visualização tem uma grande vantagem: ela funciona

Uma última coisa que eu fiz no projeto, e que não fica muito clara nas imagens, é o tratamento de dados faltantes: o que fazer se o usuário põe um nome ou sobrenome que não está nas tabelas em questão? A solução mais imediata seria simplesmente retornar uma mensagem de erro, por exemplo "O nome 'Neymar' não está disponível", mas eu imaginei que isso seria muito frustrante pra algumas pessoas e poderia acabar diminuindo o interesse na ferramenta. Uma solução melhor, ao meu ver, seria alertar ao usuário que o nome não foi encontrado, e depois dizer: "Olha, a gente não tem "Neymar", mas tem "Neimar", vou usar esse ok?". O único problema seria definir alguma métrica pra determinar "proximidade entre nomes" (ou, de forma mais geral, entre quaisquer duas palavras).
Foi assim que eu descobri que existe todo um mundo de métricas de distância entre palavras, tipo distância de Levenshtein e distância LCS, o que me parece meio natural mas eu nunca tinha parado pra pensar muito nisso. Pelo pouco que li me pareceu um problema fascinante, mas eu não estava muito na vibe de me aprofundar nisso nesse exato momento, então simplesmente escolhi a distância de Levenshtein porque me dava resultados decentes e foi a qual consegui encontrar uma implementação em javascript. Com isso, o programa estava feature-complete!

Uma consequência não-intencional desse tratamento de dados faltantes é que a ferramenta aceita quaisquer duas palavras - se ela não encontrar o nome que você botou, ela simplesmente pega a coisa mais próxima, não importa se essa coisa tiver 1 letra de diferença... ou 20.
Isso nos dá traduções como:

Sem falar na possibilidade bizarra (trazida pra mim pelo maravilhoso saint-images) de traduzir do coreano pro coreano, ou do português pro português!

Essa segunda possibilidade pode ser usada pra fazer uma tradução mais alfabeticamente próxima, por exemplo "Ana Carolina" viraria "An Ha-roo-na". O céu é o limite...
Juntando as três partes, o projeto está concluído! Estou orgulhoso com o resultado final, genuinamente acho que a ideia é boa e que a página ficou visualmente agradável. Além disso, foi legal pra mim aprender D3.js do zero, e também aprendi coisas interessantes sobre o alfabeto coreano. Eu tenho uma checklist mental de que um bom projeto pessoal deve atingir pelo menos dois dos três requisitos abaixo:
Então considerando que o projeto é sexy e aprendi coisas novas, estou no lucro. Amanhã vou divulgar no Twitter, e então tudo sairá de minhas mãos
Ah porra, e antes que eu me esqueça:

meu deus...